Motivation
Existing evaluation metrics for object removal exhibit systematic biases that conflict with human perception.
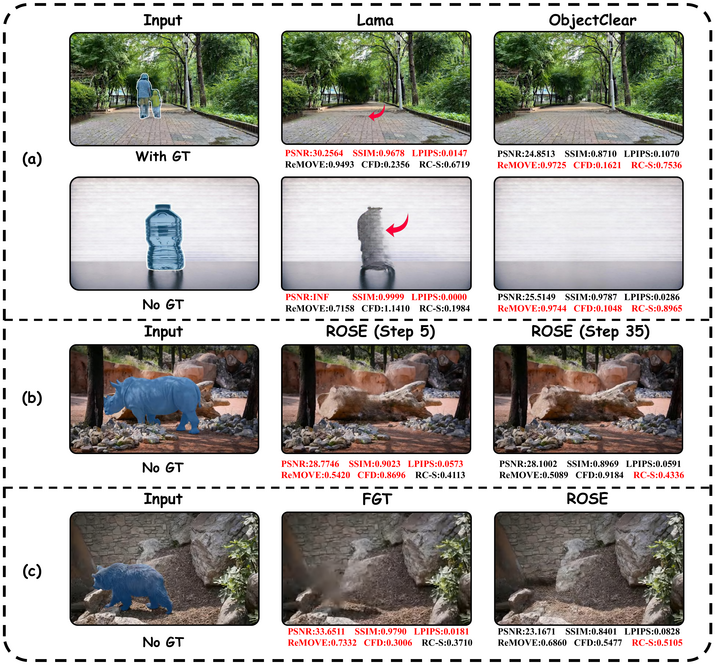
Figure 1. Illustrative examples of metric bias in object removal evaluation. (a) Full-reference metrics reward copy-paste behavior over genuine erasure. (b) No-reference metrics favor blurry outputs across diffusion steps. (c) Traditional vs. diffusion-based methods show inconsistencies between metric judgments and visual perception.

Figure 2. RC-S captures locally visible side effects and residual artifacts. Human-perceived ranking (1 = best): D > B > A > C. RC-S ranking: D(1) > B(2) > A(3) > C(4), consistent with human perception. In contrast, ReMOVE ranks A(1) > B(3) > C(4) > D(2), and CFD ranks A(1) > B(2) > C(4) > D(3) — both incorrectly favor the residual-containing result A over the cleanest removal D.
Full-Reference Bias
FR metrics (PSNR, SSIM, LPIPS) assume strict point-to-point correspondence to a single reference, rewarding conservative copy-paste outputs over perceptually realistic restorations.
No-Reference Blind Spots
NR metrics like ReMOVE and CFD frequently assign inflated scores to blurry outputs and incorrectly penalize structurally sound restorations in complex occlusion scenarios.
Temporal Insensitivity
Global temporal metrics (TC, TF) are dominated by unchanged background regions, failing to detect localized artifacts within the removed regions where object removal most commonly fails.
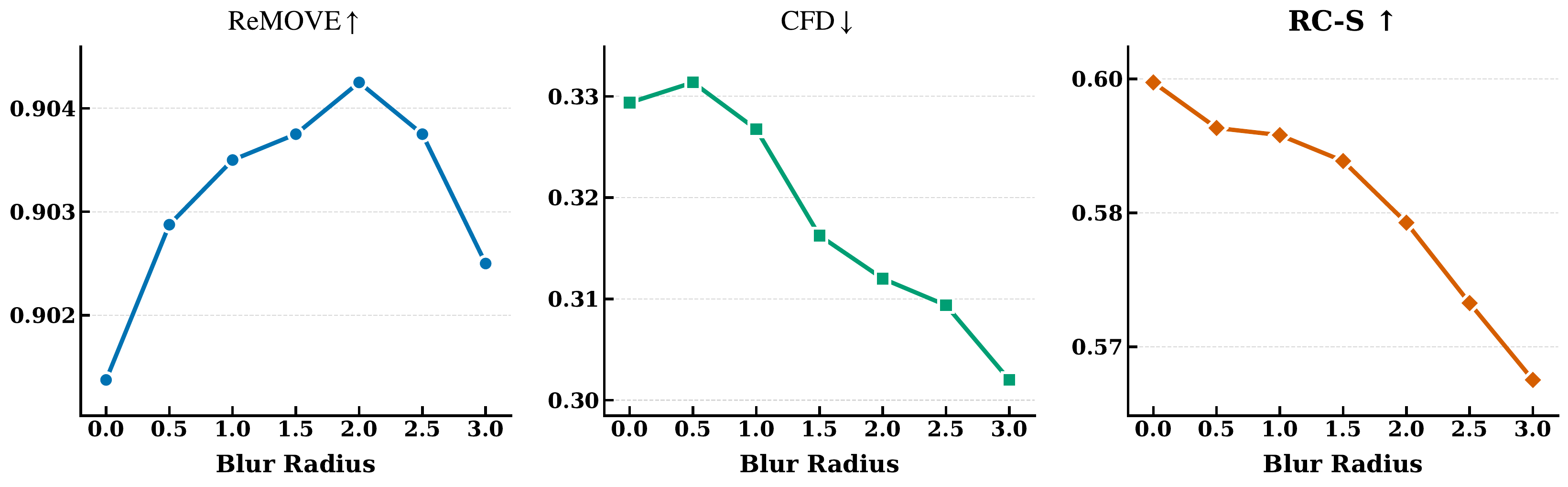
Figure 3. “Blur is Clean” bias analysis. As blur radius increases inside the masked region, ReMOVE scores incorrectly improve and CFD incorrectly decreases (appears better), while RC-S correctly and monotonically degrades — demonstrating its robustness against the blur-favoring bias.